
How many number systems are out there? When I finished my dissertation in 2003, I described my work as analyzing “over 100” structurally distinct numerical notations. Counting them is really impossible, because no one knows what ‘structurally distinct’ means. Does it ‘count’ as a distinct system when, in Western Europe, folks started to use numeral delimiter commas (26,000 vs. 26000) or decimal points? I was hopelessly trying to give a number, without necessarily counting the dozens of decimal, positional systems of the broader Indo-Arabic family. All those systems descended from the positional variants of the Brahmi numerals that originated in early medieval India, in which all sorts of script traditions use ten signs for 0-9 but substitute local signs. We can call those all different systems, or we can not, depending on our perspective.
But then by the time my dissertation became a full-fledged book, Numerical Notation: A Comparative History, in 2010, having been poked and prodded by no fewer than 14 peer reviewers (yes, really!!!), more systems were added. I stuck with “over 100” because, well, that’s technically true, but by that point it was many more than that. And I keep finding more. There’s so much out there that hasn’t been accounted for. I was going over some notes earlier this week and there are at least 25 notations on my ‘to add’ list not described anywhere in the synthetic / comparative literature. Probably closer to 50, and counting. Part of the challenge is that these are notations that are peripheral to the concerns of the major traditions of philology, epigraphy, and the history of science. I don’t think I missed any well-known ones! Some of them may have been used by only a handful of individuals, or for a short time. But there are a lot of them – far more than I would have guessed when I started on this wild path.
In a single article (cited only four times since publication), M.A. Jaspan (1967) described not one but two numerical notation systems used by speakers and writers of Rejang, a language of southwestern Sumatra. Other than technical reports by Miller 2011 and Pandey 2018 for Unicode encoding, basically no one has ever acknowledged or discussed them:
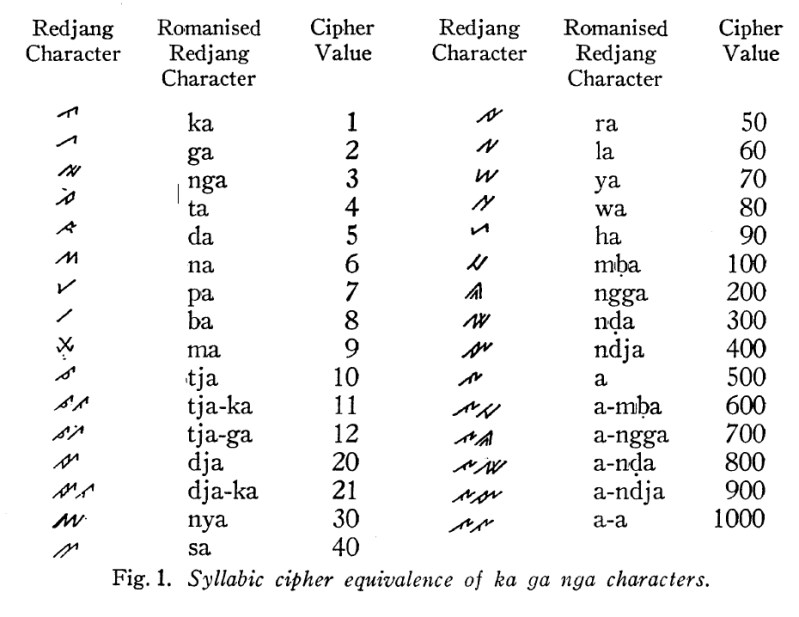
This first system may look unusual, but it is part of a broad tradition of aksharapallî systems, which use the alphasyllabaries (abugidas) of South and Southeast Asia, in their customary order, to assign numerical values to specific syllables (Chrisomalis 2010: 212-213). Here, the 23 signs (with the implied vowel ‘a’) correspond to 1-9, 10-90, and 100-500, and then for the higher hundreds, two signs combine additively. This system doesn’t have a zero – each multiple of each power of the base (10) gets its own sign, so it’s what I’ve classified as ciphered-additive – like Greek, Hebrew, and Arabic alphabetic numerals, or Cherokee, Jurchin, or Sinhalese, among others. Jaspan is dead wrong in writing (1967: 512) that “It has, as far as I know, no parallel or similarity to, other known systems either in South-East Asia or elsewhere.” Aksharapallî systems were once widespread throughout South and Southeast Asia, and are used for various purposes, including pagination, which is exactly what Jaspan reports that at least some Rejang writers used them for during his fieldwork in the early 1960s.

The second system is in some ways, even more striking. The system is structurally almost identical to the Roman numerals – there are signs for each power of 10, as well as the quinary halves 5 and 50. The hundreds are still additive but have some more complexities, and then the thousands don’t have a quinary component at all. These sorts of systems that rely on repeated signs within each power, and don’t use place-value, are called cumulative-additive and are very common throughout the Near East and the Mediterranean but relatively rare in East and Southeast Asia (though there are systems like the Ryukyuan suchuma that have this structure). I have absolutely no idea where it came from – unlike the first system, it doesn’t have any obvious relatives. At least for Jaspan’s consultants, it was used for keeping business accounts in the 1960s, though not widely.
The standard history of numerical notation is one where all systems gave way to a single, universalizing notation, the digits 0123456789, which spread globally without competition. And there’s certainly a point to be made there. But there is a countervailing factor, the inventive impetus under which we can expect all sorts of notations to be invented, perhaps not with global reach, but of critical importance for understanding the comparative scope of the world’s numerical systems. In my new book, Reckonings: Numerals, Cognition, and History (Chrisomalis 2020), I make the case that we are not at the ‘end of history’ of numeration – that innovation continues apace in this domain, and that focusing only on the well-known systems produces a very barren history. Cases like the Rejang numerals help produce a richer narrative – one of constant and ongoing numerical innovation.
References
Chrisomalis, Stephen. Numerical notation: A comparative history. Cambridge University Press, 2010.
Chrisomalis, Stephen. Reckonings: Numerals, cognition, and history. MIT Press, 2020.
Jaspan, Mervyn Aubrey. “Symbols at work: Aspects of kinetic and mnemonic representation in Redjang ritual.” Bijdragen tot de Taal-, Land-en Volkenkunde 4de Afl (1967): 476-516.
Miller, Christopher. “Indonesian and Philippine Scripts and extensions not yet encoded or proposed for encoding in Unicode as of version 6.0.” (2011).
Pandey, Anshuman. “Preliminary proposal to encode Rejang Numbers in Unicode.” (2018).

That’s not as simple as “Western Europe”. English uses decimal points, and commas for thousands. Switzerland (all languages) uses apostrophes for thousands. The rest of Europe uses decimal commas, and points and/or spaces for thousands.
Yes, absolutely! If it were more directly on point to this blog post, I would have gone through some of those variations. And in India, the delimiter comma (beyond the first 3) is every 2 places, instead of every 3 (e.g. 1,000,000 ==> 10,00,000), because of the structure of Hindi (and other Indic languages’) numeral words. Are these each ‘separate systems’? It isn’t really solvable in a non-arbitrary way.